728x90
기존 엑셀 파일에 이어서 저장하는 법
첫 페이지 1페이지
# step 1 : 새로운 엑셀 파일에 저장하기
import requests
from bs4 import BeautifulSoup
import pandas as pd
data = []
for i in range(1, 2):
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name > a").attrs['href']
price = item.select_one(".product-price").text.split('원')[0].replace(',','')
print(category, name, link,price)
data.append([category,name,link,price])
# 데이터 프레임 만들기
df = pd.DataFrame(data,columns=["카테고리","상품명","상세페이지링크","가격"])
# 엑셀 저장
df.to_excel('result.xlsx', index=False)
# 자동생성 인덱스 번호 제거
#df.to_excel('result.xlsx', index=False)
두 번째 페이지 2페이지
*1페이지 뒤에 2페이지 데이타 엑셀파일 합치기
# step 2 : 기존 엑셀 파일에 추가해서 저장하기
import requests
from bs4 import BeautifulSoup
import pandas as pd
data = []
for i in range(2, 3):
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name > a").attrs['href']
price = item.select_one(".product-price").text.split('원')[0].replace(',','')
print(category, name, link,price)
data.append([category,name,link,price])
# 데이터 프레임 만들기
df = pd.DataFrame(data,columns=["카테고리","상품명","상세페이지링크","가격"])
# 기존 엑셀 파일 불러오기
existing_df = pd.read_excel('result.xlsx')
#기존 데이터프레임에 새 데이터 추가
#ignore_index 인덱스는 무시하고 합쳐라
update_df = pd.concat([existing_df,df], ignore_index=True)
# 엑셀 저장
update_df.to_excel('result.xlsx', index=False)
# 자동생성 인덱스 번호 제거
#df.to_excel('result.xlsx', index=False)
더 알고 싶다면 pandas 데이터 분석파트 공부하셈
새로운 시트에 엑셀 파일에 저장하기
세 번째 페이지 3페이지
# step 3 : 새로운 시트에 저장하기
import requests
from bs4 import BeautifulSoup
import pandas as pd
data = []
for i in range(3, 4):
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.select(".product")
for item in items:
category = item.select_one(".product-category").text
name = item.select_one(".product-name").text
link = item.select_one(".product-name > a").attrs['href']
price = item.select_one(".product-price").text.split('원')[0].replace(',','')
print(category, name, link,price)
data.append([category,name,link,price])
# 데이터 프레임 만들기
df = pd.DataFrame(data,columns=["카테고리","상품명","상세페이지링크","가격"])
# 'ExcelWriter' <- 판다스에서 특정 라이브러리의 기능을 가져다 쓰기 위해 사용하는 녀석
# 'with' <= 파일을 열었을때 파일객체를 자동으로 관리해주는 구문 (ex 파일을 열고나서 닫아야하는데 with가 자동으로 해줌)
# 'mode='a' <= 기존 엑셀파일을 추가모드로 연다
# 'engine='openpyxl' <= openpyxl라이브러리의 도움을 받아서 ExcelWriter을 만들겠다는 뭐 그런 뜻
# 'ExcelWriter' 를 사용하여 기존 엑셀 파일 열기
with pd.ExcelWriter('result.xlsx', mode='a', engine='openpyxl') as writer:
#새로운 시트에 데이터 저장
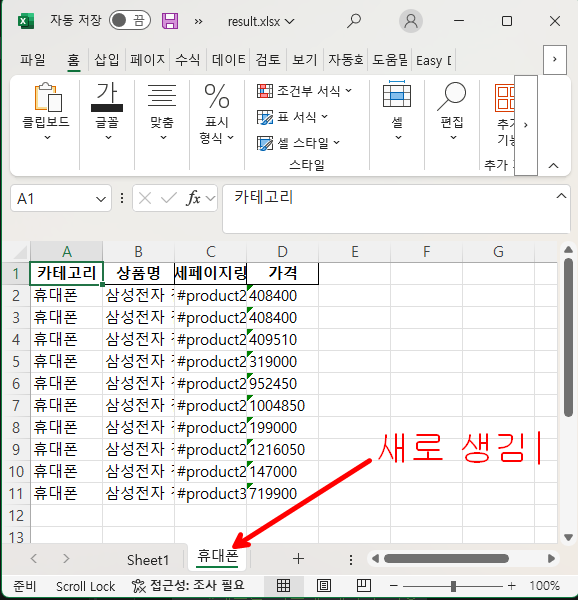
df.to_excel(writer, sheet_name='휴대폰', index=False)
실행후 엑셀 열어보면
'Python > BeautifulSoup' 카테고리의 다른 글
| [크롤링] 파이썬으로 간단하게 크롤링하기 보너스. (문자열 처리 함수) (0) | 2024.10.11 |
|---|---|
| [크롤링] 파이썬으로 간단하게 크롤링하기6. (데이터 엑셀에 저장) (1) | 2024.10.08 |
| [크롤링] 파이썬으로 간단하게 크롤링하기5. (여러개 페이지 크롤링 , URL 조작자) (0) | 2024.10.08 |
| [크롤링] 파이썬으로 간단하게 크롤링하기4. (여러개 상품 크롤링 하는 법) (0) | 2024.10.08 |
| [크롤링] 파이썬으로 간단하게 크롤링하기3. (한개의 상품 크롤링) (0) | 2024.10.08 |


