https://deahan.tistory.com/418
[크롤링] 파이썬으로 간단하게 크롤링하기1. (환경설정)
1. 파이썬 설치2. VScode 설치3. VScode 확장 프로그램 및 주피터 노트북 사용 1.파이썬 설치https://www.python.org/downloads/ Download PythonThe official home of the Python Programming Languagewww.python.org 현재 python 3.12.
deahan.tistory.com
여기까지 환경설정(5분도 안걸림)을 마쳤다면~~~
이번엔 라이브러리 사용법이다.
따라하자
1.requests 사용법

첫 번째 박스
pip install requests -> requests 라이브러리 설치
두 번째 박스
pip install bs4 -> Beautifulsoup4 라이브러리 설치
세 번째 박스
requests 라이브러리를 import하고 라이브러리를 사용해 크롤링할 url을 적어줌
네 번째 박스
실행했을때 200은 정상적으로 실행 되었다. 404는 못찾는 페이지다.
마지막 response.text
요청한 url에서 text형식으로 모든 페이지 정보를 받아옴
여기서 text가 한줄로나와 보기 어려운데
개요 옆에 ˙ ˙ ˙버튼 클릭하고 -> 노트북 레이아웃 사용자 지정 클릭

쭉 내리다 보면
Notebook > output:Word Wrap 보임

체크박스에 체크 하고 돌아와서 다시 코드를 돌려보면 줄바꿈이 되었음

어쨋든 받아온 페이지 정보가 text형식이라 보기 힘들어서
Beautyfulsoup4의 도움을 받아
HTML형식으로 바꿔주고 원하는 데이터를 쏙쏙 뽑아와보자!!
코드 작성 왼쪽 ...눌러서 셀 출력 지우기 선택후
아래 코드 복붙 후 실행
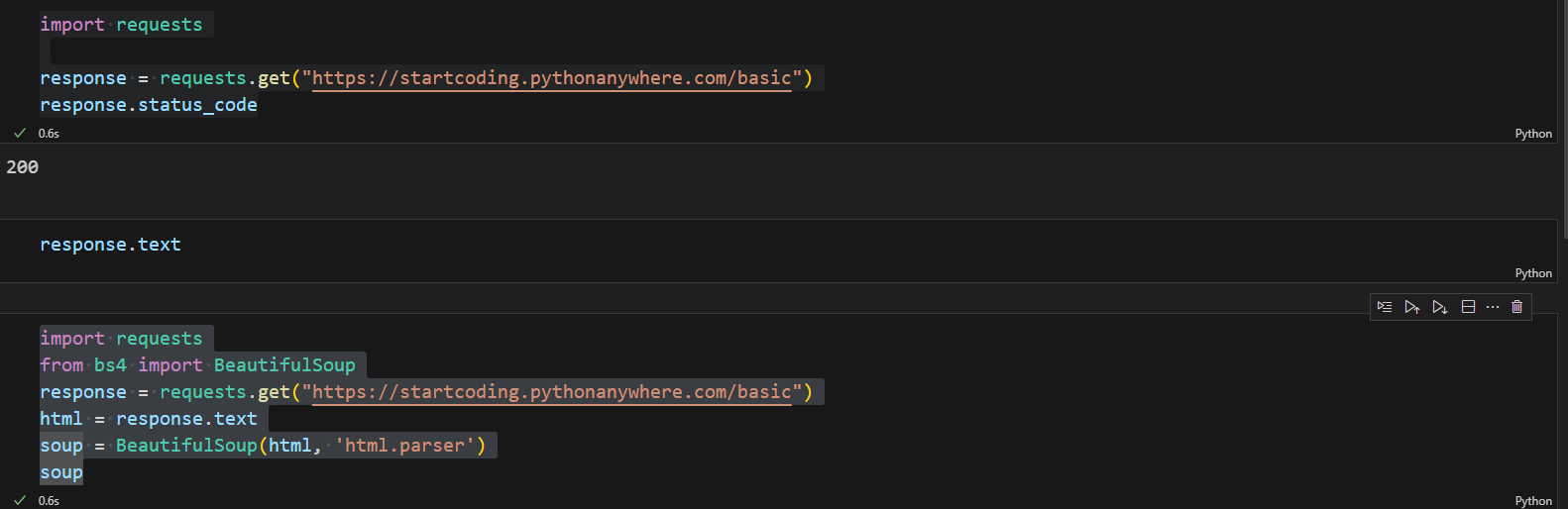
설명
html = html변수에 response로 받아온 text 저장
soup = BeatifulSoup(html, 'html.parser') html.parser가 html 태그들을 인식하고 하나씩 줄바꿈해줌(파싱)
그리고 soup출력하면 아래와 같이 보기 편해짐
이코드는 계속 복붙할 것임
그리고 ctrl + url을 선택하면 해당 페이지로 이동함
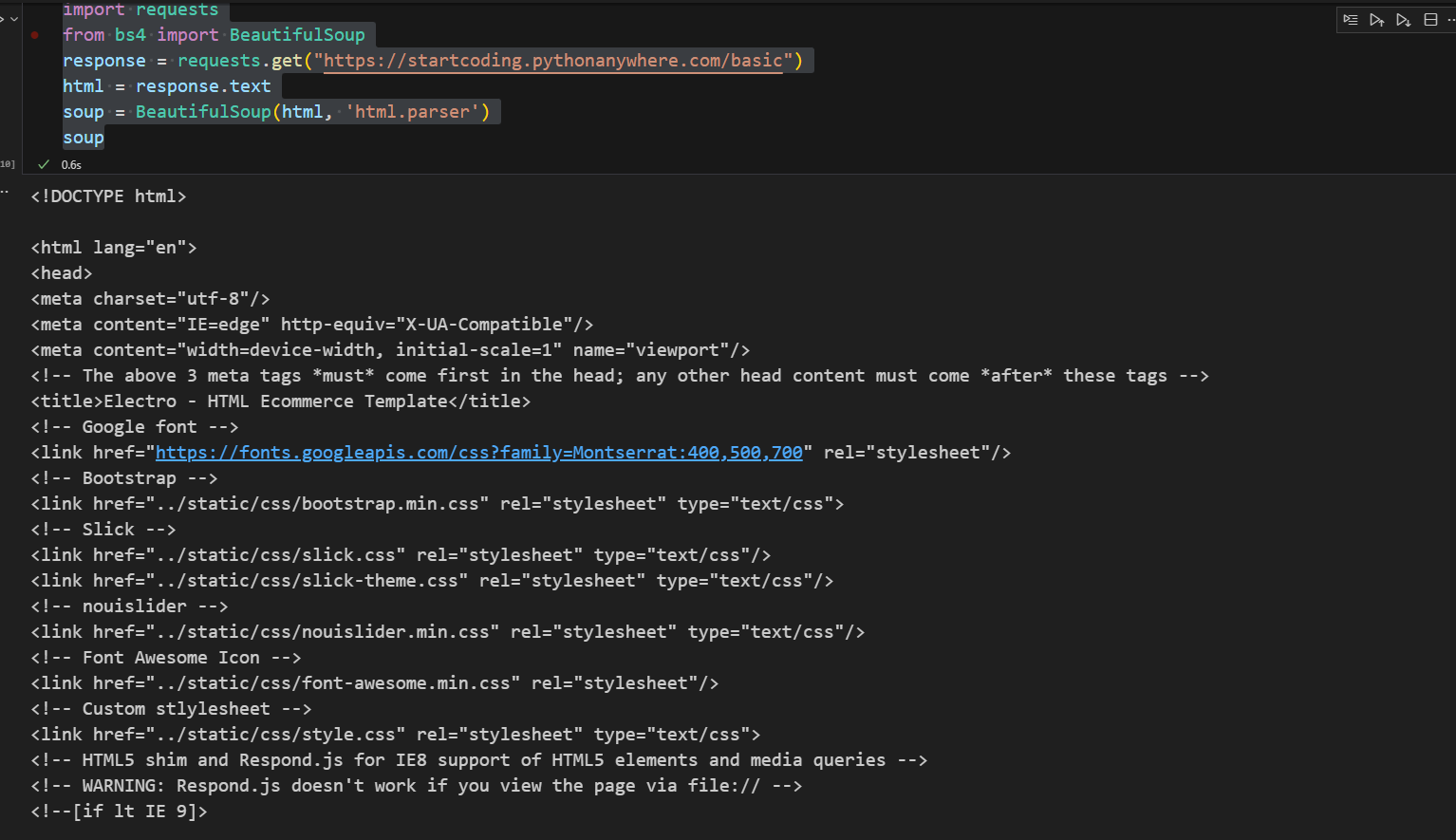
여기까지 하면 데이터를 추출할 준비가 끝남
추출 방법은
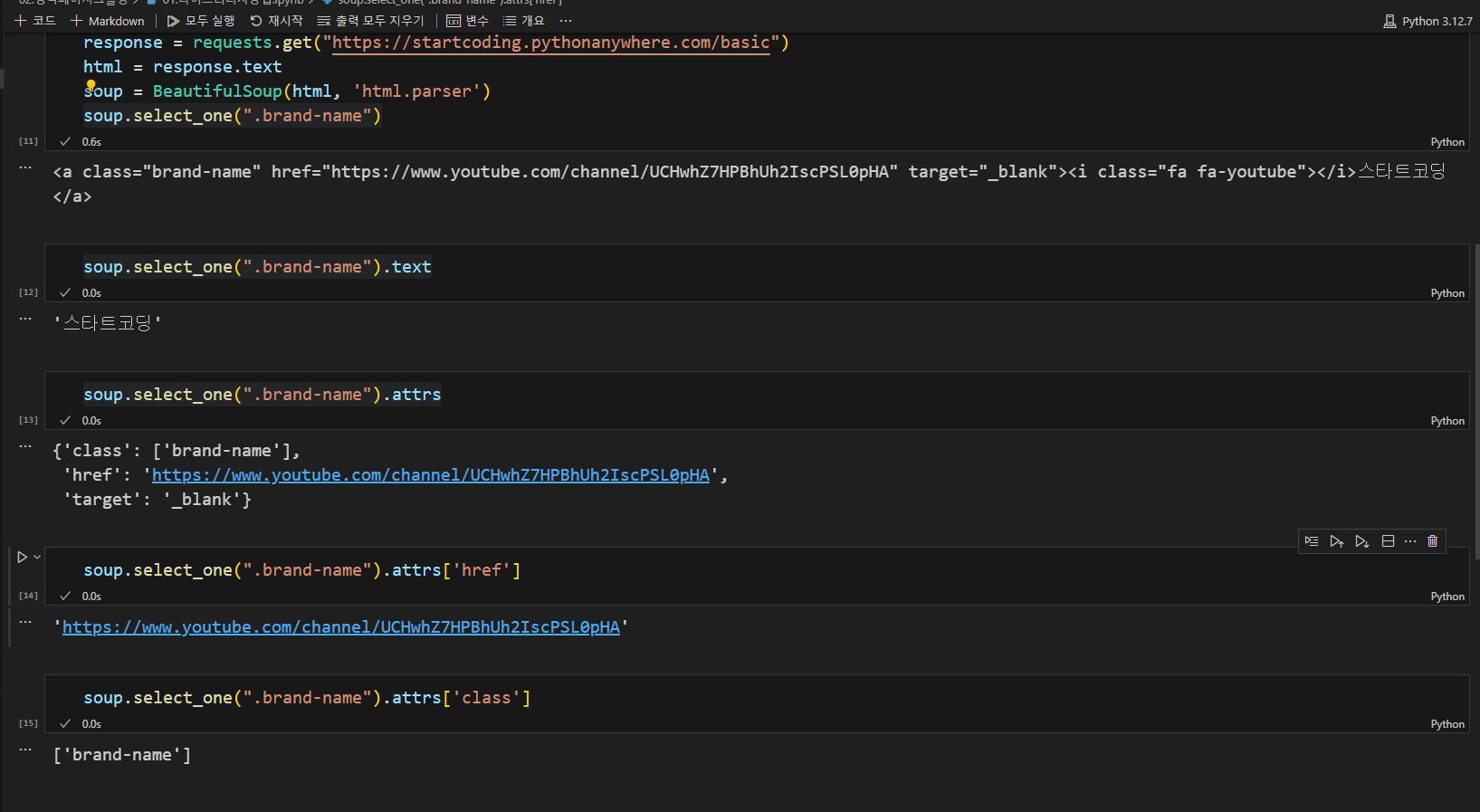
soup.select_one("선택자")
select_one() 함수는 무조건 하나의 선택자만 가져옴
값이 여러개면 첫번째거 가져옴
나는 해당 페이지에서
아래 빨간색 박스 쳐진 스타트 코딩이라는 text뽑아올거임
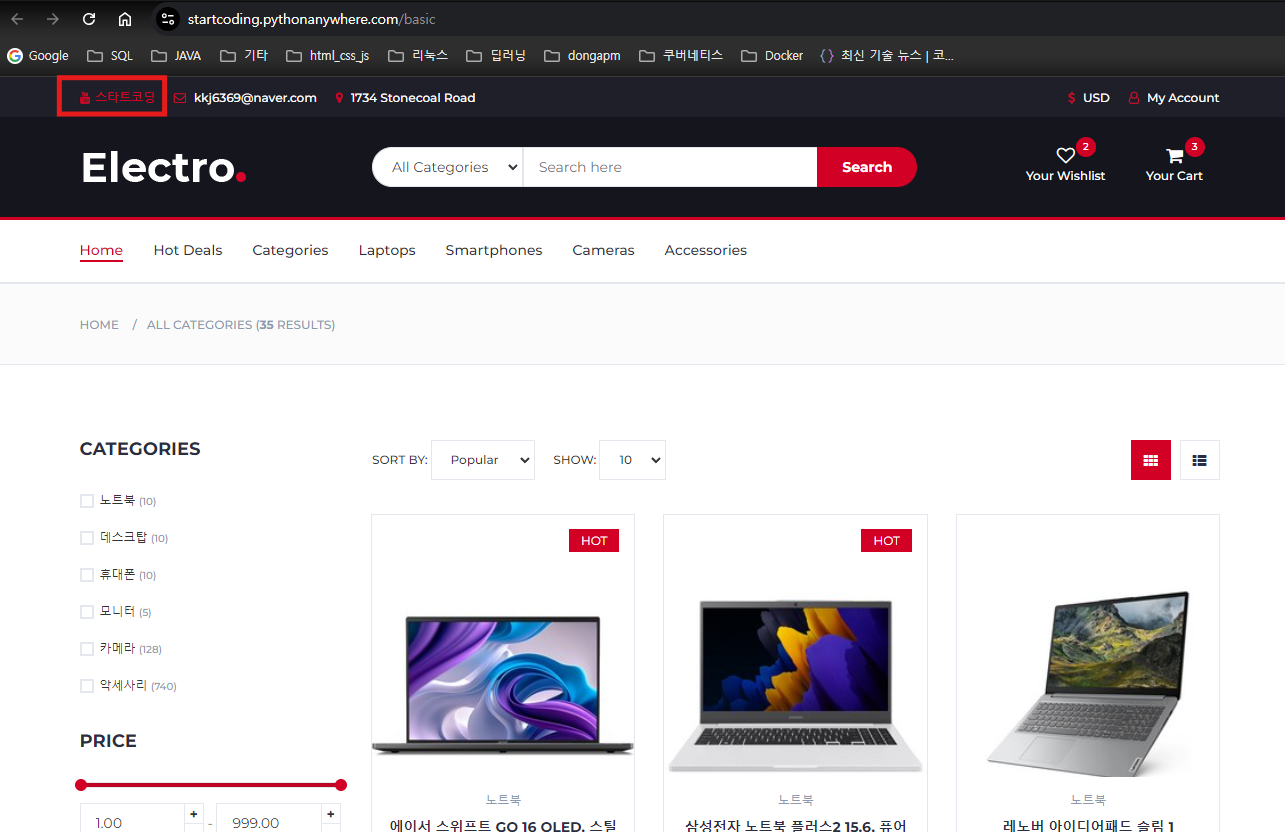
개발자 도구 실행하고
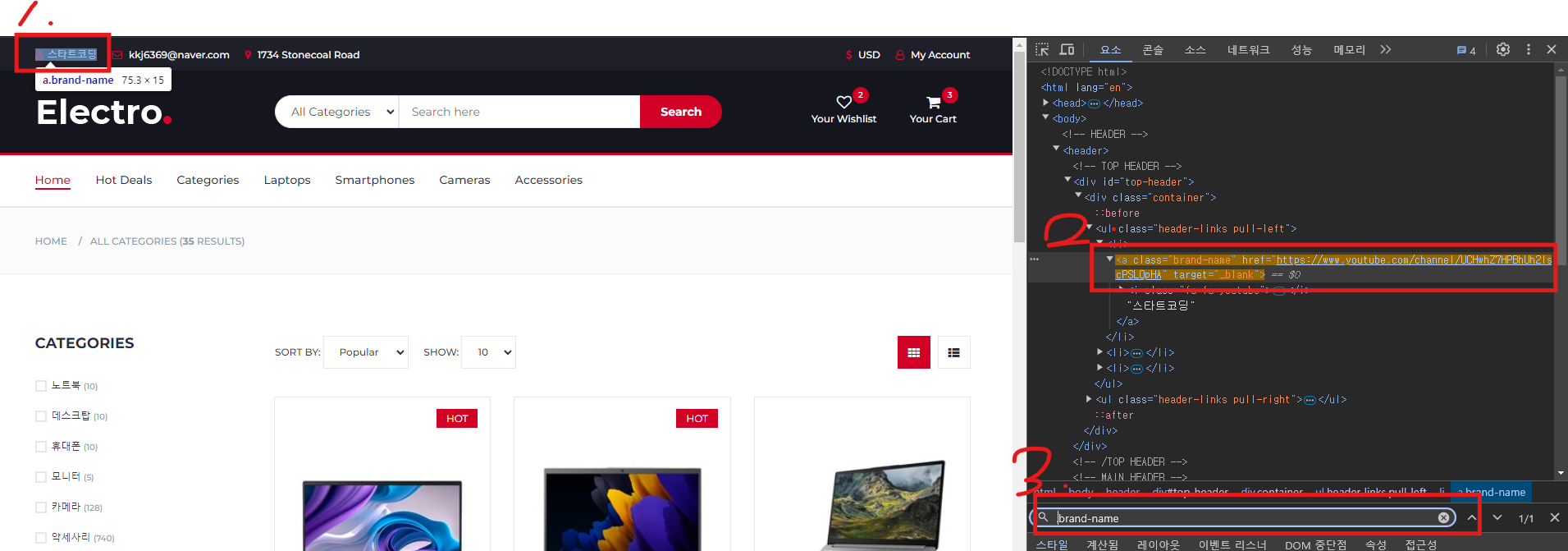
1.뽑아올 데이터 선택
2.선택자 확인 class가 .brand-name인것을 확인
개발자도구에서 .brand-name 더블클릭하고 ctrl+f 눌러서
3.클래스 검색을해본다 그럼 오른쪽에 1/1 몇개중에 몇번째 뜸!! 근데 이건 하나임
코드로 가서 실행
여러가지 테스트 하면 끝
이렇게 아래 처럼 원하는 데이터만 쏙쏙 뽑아올 수 있다.
다음은 한개의 상품 크롤링하기다..
https://deahan.tistory.com/421
[크롤링] 파이썬으로 간단하게 크롤링하기3. (한개의 상품 크롤링)
https://deahan.tistory.com/419 [크롤링] 파이썬으로 간단하게 크롤링하기2. (Beautifulsoup4, request라이브러리 사용법)https://deahan.tistory.com/418 [크롤링] 파이썬으로 간단하게 크롤링하기1. (환경설정)1. 파이
deahan.tistory.com
'Python > BeautifulSoup' 카테고리의 다른 글
| [크롤링] 파이썬으로 간단하게 크롤링하기4. (여러개 상품 크롤링 하는 법) (0) | 2024.10.08 |
|---|---|
| [크롤링] 파이썬으로 간단하게 크롤링하기3. (한개의 상품 크롤링) (0) | 2024.10.08 |
| [크롤링] 파이썬으로 간단하게 크롤링하기1. (환경설정) (0) | 2024.10.07 |
| 파이썬(BeautifulSoup)사용해서 주식 데이터 크롤링(가져오기) (0) | 2023.07.08 |
| 파이썬(BeautifulSoup) 원하는 데이터 크롤링 하기 (0) | 2023.07.07 |



